Adding Batched Tensor Dot + Simplifying API#309
Conversation
Codecov Report
@@ Coverage Diff @@
## main #309 +/- ##
==========================================
+ Coverage 85.07% 89.74% +4.67%
==========================================
Files 95 97 +2
Lines 5125 5217 +92
==========================================
+ Hits 4360 4682 +322
+ Misses 765 535 -230
Continue to review full report at Codecov.
|

|
|
||
| Parameters | ||
| ---------- | ||
| modes : int or tuple[int] or (modes1, modes2) |
There was a problem hiding this comment.
How do you distinguish between the second and third case?
a_shape = (5, 4, 5)
b_shape = (8, 4, 5)
_validate_contraction_modes(a_shape, b_shape, (1,2))currently returns an error. I think we should remove the second case from the docstring. This will also keep it consistent with tl.tensordot.
There was a problem hiding this comment.
I was hesitant about this very usecase. It is convenient to be able to pass a tuple in. But then the case where it's of length 2 is indeed ambiguous, so I left the error. Might indeed be best to keep it consistent with tensordot.
| from math import prod | ||
|
|
||
|
|
||
| def batched_tensor_dot(tensor1, tensor2, modes, batched_modes=()): |
There was a problem hiding this comment.
I think we should change its name to batched_tensordot to both be consistent with tenordot and to differentiate it with the removedtl.tenalg.batched_tensor_dot which was an outer product.
There was a problem hiding this comment.
I'm conflicted - I have implemented other version for factorized tensors, e.g. tensor_dot_tucker or tucker_dot_tucker. It would be more consistent to use x_dot_y everywhere. I don't think differentiating with the previous one is necessary - we can document the change and it wasn't used anywhere in the library anyway.
However, being consistent with Numpy might be reason enough. If we go for batched_tensordot we could actually consider just calling it tensordot, with an additional batched_modes parameter.
|
So the two upstanding questions would be: Naming (
|
|
Renamed the function to |
Batched tensor-dot
This PR adds a new
batched_tensor_dotfunction. It extends the signature of the standardtensordotfunction by adding abatched_modesparameters. It also fixes #250.The signature is
API simplification
Using the new batched-tensordot, we can simplify the overall API so I removed the existing
outer,contract,tensor_dotandbatched_tensor_dot. These are all encompassed in the new function.I generalized the existing
outerfunction and addedbatched_outer, which now both support lists of tensors of arbitrary shapes, and leftinnerfor convenience for end users, though I think this can also be removed.Implementation
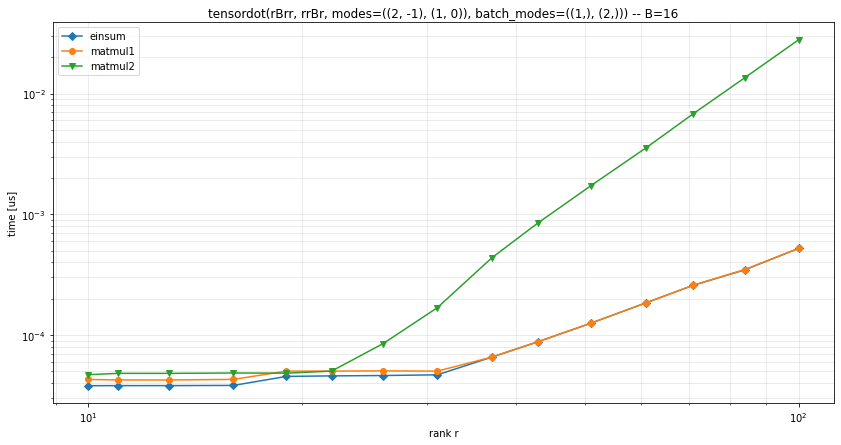
I've written a few versions and ran some comparisons. For the
einsumtenalg backend there's an einsum version and I've tried a few versions using matmul or even just broacasting + sum.Note that the last implementation is mostly a proof of concept for tests and is very memory inefficient.
Performance
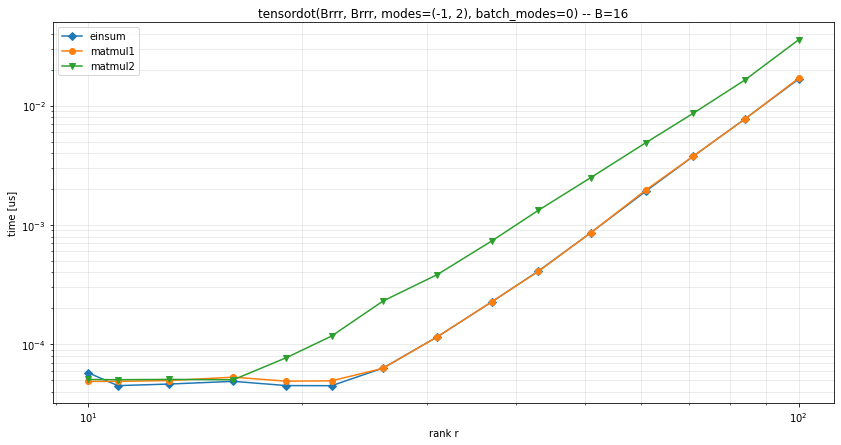
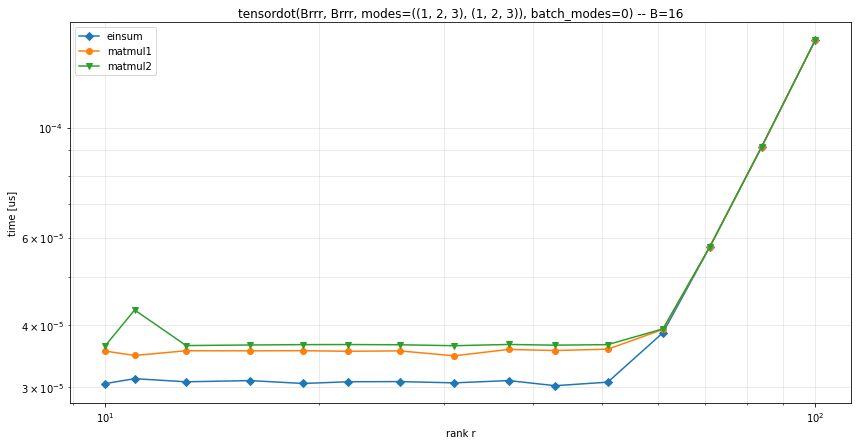
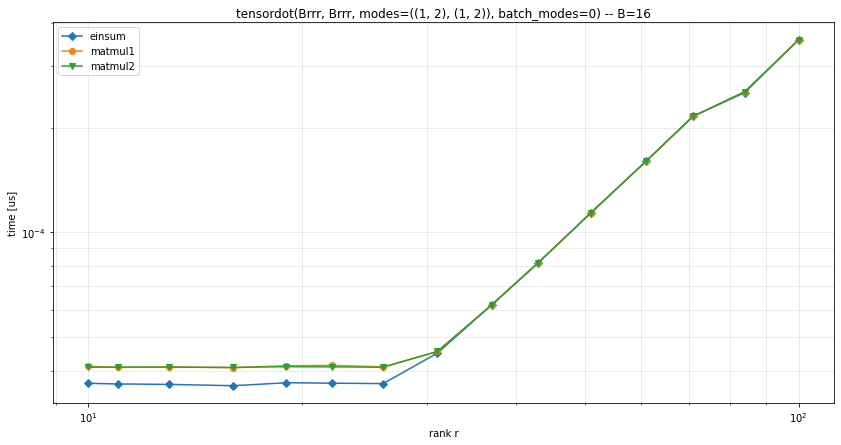
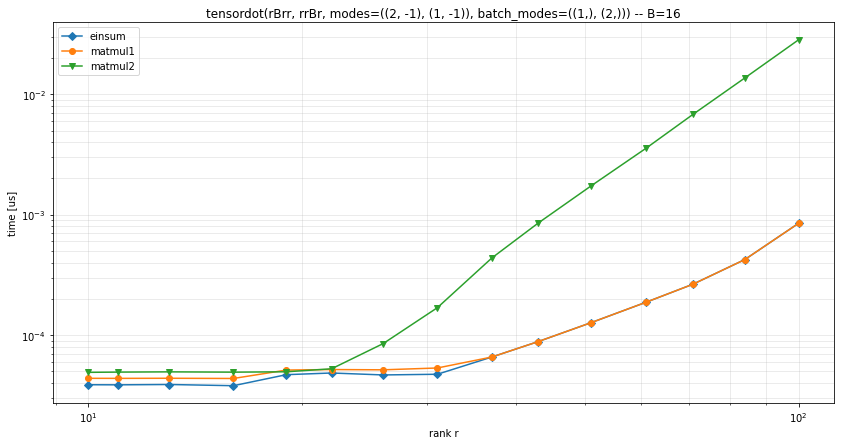
I ran some timings on a GPU with the pytorch backend, in several configurations:
Block TT contraction
This use-case happens when manipulating Block TT decompositions.
Other configurations
It seems that
einsumandmatmul1version are overall the best ones.Some more timings: